
大規模言語モデルFoxBrain
鴻海(フォックスコン)は3月10日、推論能力を持つ繁体字中国語の大規模言語モデル(LLM)を発表しました。いずれは、AI大規模言語モデルの導入によって、スマート・マニュファクチャリング、スマートモビリティ、スマートシティなど3大プラットフォームのデータ分析の効率を強化していきます。
鴻海は、同モデルの学習過程で、輝達(エヌビディア)がTaipei-1スーパーコンピュータと技術コンサルタントを提供し、NeMoの使用を許可したため、学習がスムーズに進んだと説明しています。
プレスリリースで発表された繁体字中国語の大規模言語モデルFoxBrainは、もともと社内用に設計されており、データ分析、意思決定支援、文書作成、数学、問題解決やコード生成などの機能を持ち、将来的にはオープンソース化されます。同モデルを外部と共有することで、適用範囲を拡大し、技術パートナーとともに、製造業、サプライチェーンの管理、意思決定などのAI化を推進していく予定です。
FoxBrainのテスト結果
FoxBrainは、鴻海研究所のAI推論LLMモデルトレーニングの成果であり、理解と推論能力を持ち、数学と論理的推論のテストで優秀な成績を収め、繁体字中国語能力も優れています。
「FoxBrainはNVIDAのH100GPUを120チップ使用し、NVIDIA Quantum-2 InfiniBandを通してネットワークに接続したため、わずか4週間でトレーニングが完了し、効率的かつ低コストであった」と鴻海研究所は説明しています。
トレーニング戦略ですが、FoxBrainは独自の技術を用い、24種類のトピックデータを使った強化モデルと品質評価方法を確立しました。中国語のトレーニングデータである98Bトークンを生成し、128Kコンテキスト長を実現、消費した総計算力は2688 GPU daysです。効率の良さと安定性を確保するため、マルチノード並列学習環境を採用しました。
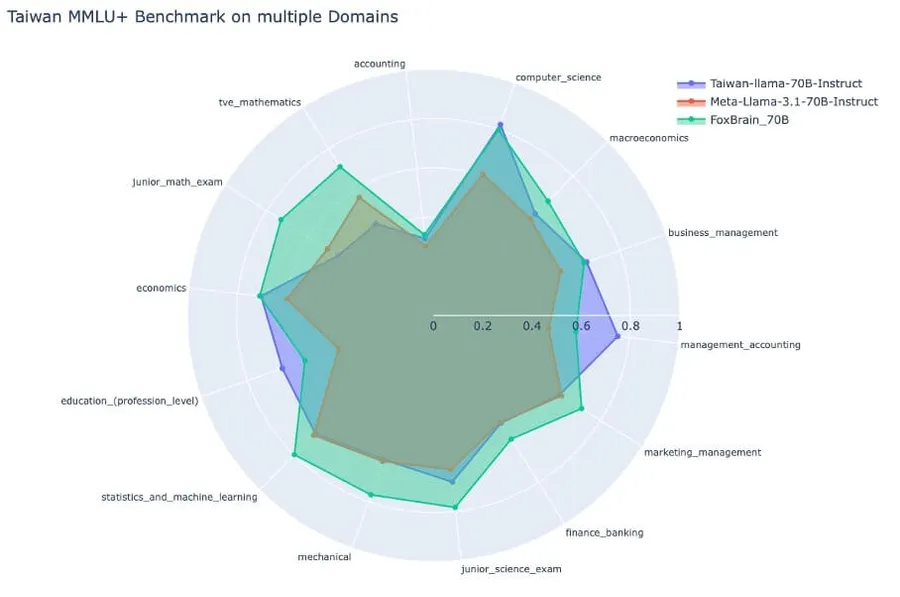
テスト結果を見ると、FoxBrainの基礎モデルMeta Llama 3.1と比べ、数学の分野が改善されました。現在、台湾で最も優れている繁体字中国語大規模言語モデルTaiwan Llamaと比較すると、数学の分野で大きな進歩を遂げ、Metaがリリースする同レベルのモデルを上回ります。DeepSeek蒸留モデルとは未だ少し差はありますが、世界のトップレベルの水準に近づいています。
鴻海は、米国時間3月17日に行われるNVIDIA GTC 2025の講演会「From Open Source to Frontier AI: Build, Customize, and Extend Foundation Models」でFoxBrainの成果を初めて一般に向けて発表する予定です。
引用元:https://www.bnext.com.tw/article/82574/foxconn-traditional-chinese-ai-model